Pre-requisite : Trie
Suffix tree is a compressed trie of all the suffixes of a given string. Suffix trees help in solving a lot of string related problems like pattern matching, finding distinct substrings in a given string, finding longest palindrome etc. In this tutorial following points will be covered:
- Compressed Trie
- Suffix Tree Construction (Brute Force)
- Brief description of Ukkonen's Algorithm
Before going to suffix tree, let's first try to understand what a compressed trie is.
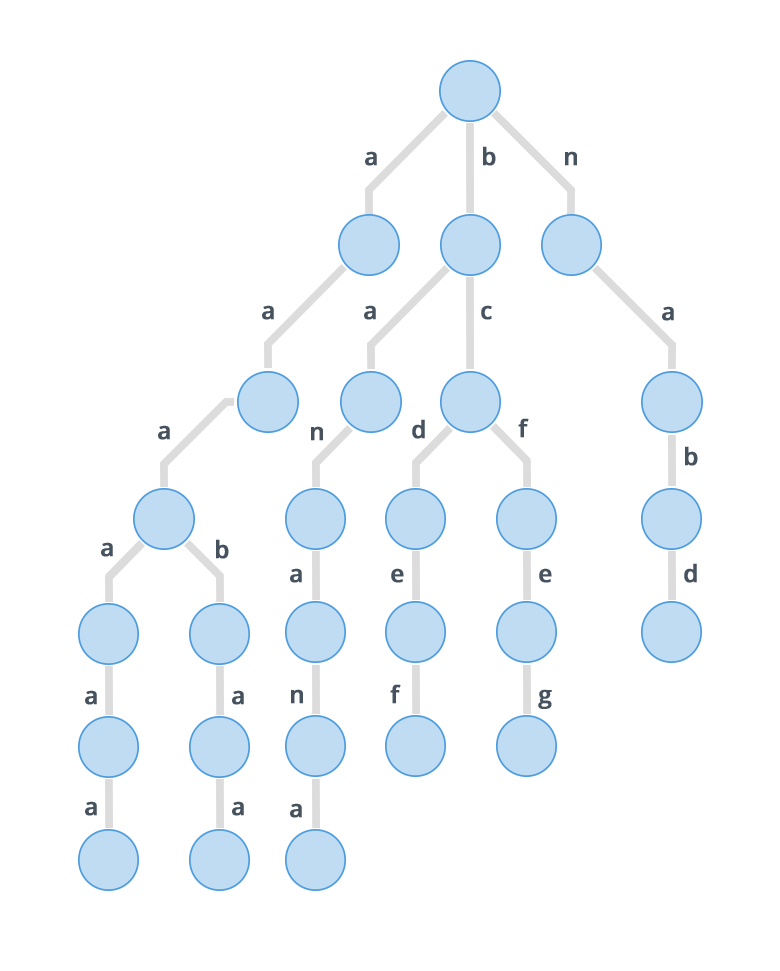
Consider the following set of strings: { }
A standard trie for the above set of strings will look like:
And a compressed trie for the given set of strings will look like:
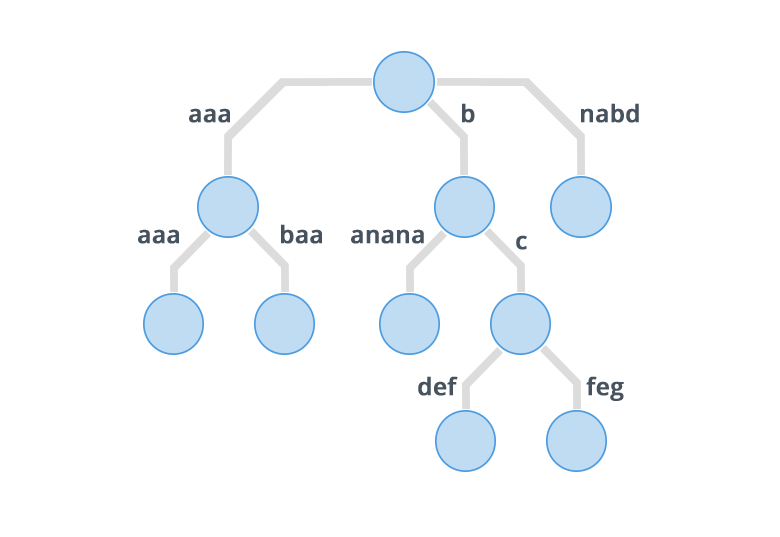
As it might be clear from the images show above, in a compressed trie, edges that direct to a node having single child are combined together to form a single edge and their edge labels are concatenated. So this means that each internal node in a compressed trie has atleast two children. Also it has atmost leaves, where is the number of strings inserted in the compressed trie. Now both the facts: Each internal node having atleast two children, and that there are leaves, implies that there are atmost nodes in the trie. So the space complexity of a compressed trie is as compared to the of a normal trie.
So that is one reason why to use compressed tries over normal tries.
Before going to construction of suffix trees, there is one more thing that should be understood, Implicit Suffix Tree. In Implicit suffix trees, there are atmost leaves, while in normal one there should be exactly leaves. The reason for atmost leaves is one suffix being prefix of another suffix. Following example will make it clear. Consider the string
Implicit Suffix Tree for the above string is shown in image below:
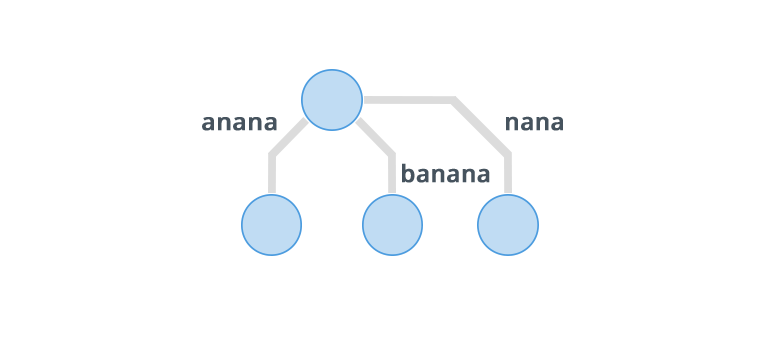
To avoid getting an Implicit Suffix Tree we append a special character that is not equal to any other character of the string. Suppose we append $ to the given string then, so the new string is . Now its suffix tree will be
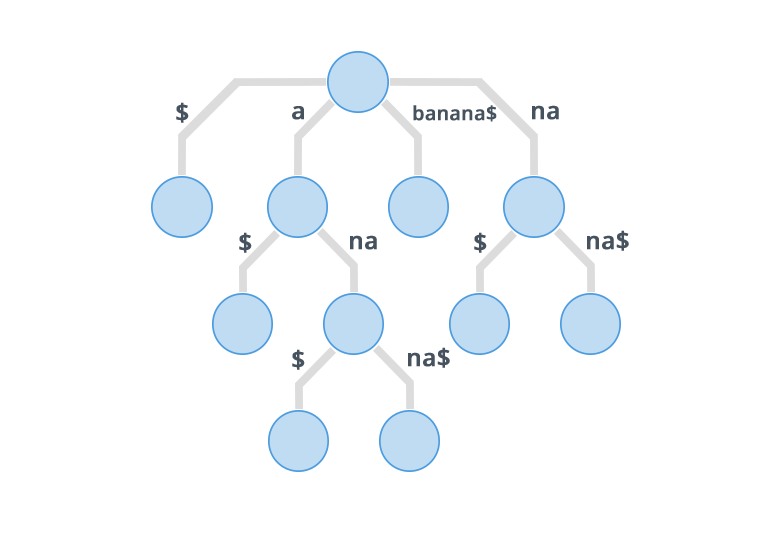
Now let's go to the construction of the suffix trees.
Suffix tree as mentioned previously is a compressed trie of all the suffixes of a given string, so the brute force approach will be to consider all the suffixes of the given string as separate strings and insert them in the trie one by one. But time complexity of the brute force approach is , and that is of no use for large values of .
Implicit Suffix Tree for the above string is shown in image below:
To avoid getting an Implicit Suffix Tree we append a special character that is not equal to any other character of the string. Suppose we append $ to the given string then, so the new string is . Now its suffix tree will be
Now let's go to the construction of the suffix trees.
Suffix tree as mentioned previously is a compressed trie of all the suffixes of a given string, so the brute force approach will be to consider all the suffixes of the given string as separate strings and insert them in the trie one by one. But time complexity of the brute force approach is , and that is of no use for large values of .
The pseudo code for the brute force approach is given below:
function insert(T, string, start_index, length){
i = start_index
while(i < length)
if T.arr[string[i]]) is NULL
T.arr[string[i]] = new node()
T = T.arr[string[i]]
while(i < length)
T.label = T.label+string[i]
i = i+1
endwhile
return
endif
j=0, x=i
temp = T.arr[string[i]]
while j < temp.label.length and i < length && temp.label[j] = string[i]
i = i+1
j = j+1
endwhile
if i = length
return
endif
if j = temp.label.length
cnt = 0
for k = 'a' to 'z'
if temp.arr[k] = NULL
cnt = cnt+1
endif
endfor
if cnt = 27
while i < length
temp.label = temp.label + string[i]
i = i+1
endwhile
else
T = temp
endifelse
else
newInternalNode = new node()
k=0
while k < j
newInternalNode.label = newInternalNode.label + temp.label[k]
k = k+1
endwhile
newInternalNode.arr[string[j]] = new node()
while k < temp.label.length
newInternalNode.arr[string[j]].label+=temp.label[k]
k = k+1
endwhile
for k = 'a' to 'z'
newInternalNode.arr[string[j]].arr[k] = temp.arr[k]
endfor
T.arr[string[x]] = newInternalNode
T = T.arr[string[x]]
endifelse
endwhile
}
function makeSuffixTree(string, length){
Trie T
string = concatenate(string, "{")
for i = 0 to length
insertInTrie(T, string, i, length)
}
So as mentioned previously the above code will not be correct choice for large values of Ukkonen's Algorithm comes to the rescue here.
Ukkonen's Algorithm constructs the suffix tree in a worst case time complexity of .
Ukkonen's Algorithm constructs the suffix tree in a worst case time complexity of .
Ukkonen's Algorithm divides the process of constructing suffix tree into phases and each phase is further divided into extensions. In phase character is introduced in the trie. In phase, all the suffixes of the string are inserted into the trie, and inserting suffix in a phase is called extension of that phase. So, in phase there are extensions and overall there such phases, where is the length of given string. Right now it must look like a task, but the algorithm exploits the fact that these are suffixes of same string and introduces several tricks that bring down the time complexity to .
Let's see how to perform the extension of phase. In extension of phase string is to be inserted. Before going for phase , phases are already complete, that means we have a trie having all suffixes of string . So search for the path of string in the trie. Now there are 3 possibilities and each of those correspond to one rule, that has to be followed.
- The complete string is found and path ends at a leaf node. In that case the character is appended to last edge label and no new node is created.
- The complete string is found and path ends in between an edge label, and the next character of edge label is not equal to or the path ends at an internal node. In this case new nodes are created. If the path ends in an internal node then a new leaf node is created, and if the path ends in between an edge label then a new internal node and one new leaf node is created.
- Complete suffix is found and the path ended in between an edge label and the next character of that edge label is equal to character. In that case do nothing.
So given above are the 3 extension rules used to perform extensions in a phase.
Note that still we are doing phases and in phase we are performing extensions.
For every extension we need to find the path of a string in the trie built in previous phases. If we go with brute force approach time complexity will be , for that we use suffix links, which are explained below:
Note that still we are doing phases and in phase we are performing extensions.
For every extension we need to find the path of a string in the trie built in previous phases. If we go with brute force approach time complexity will be , for that we use suffix links, which are explained below:
Suffix Links: Suppose a string is present in the trie, and its path from root ends at a node , and string is also present in the trie where is any character, and its path from root ends at a node , then a link from to is called a Suffix Link.
Now how does a suffix link help? When we have to perform extension of phase , we have to look for end of path of string , and in the next phase look for end of path of string , but before coming to phase , we have performed phases, that means we have inserted strings and in the trie. Now clearly is nothing but , so we will have a suffix link from node ending at path to node ending at path , so instead of traversing down from root for extension of phase, we can make use of the suffix link.
Use of suffix link makes processing of a phase an process, and number of nodes in a compressed trie are of . So right now each phase is done in and there are such phases, so overall complexity right now is .
Use of suffix link makes processing of a phase an process, and number of nodes in a compressed trie are of . So right now each phase is done in and there are such phases, so overall complexity right now is .
Before going further there is one more problem, and that is the edge labels. If the edge labels are stored as strings space complexity will turn out to be , no matter the what the number of nodes are. So for that instead of using strings as edge label, use two variables for each label and those will denote the start index and end index of the label in the string. That way each label will take constant space and overall space complexity will be .
There are several more tricks that help in bringing down the complexity to linear.
In any phase, the extension rules are applied in the order. In first few extensions, rule 1 is applied, in the next few extensions rule 2 is applied and in the rest rule 3 is applied.
If in phase rule 3 is applied in extension for the first time, then in all the extensions after that i.e. in extensions to , rule 3 will be applied, so its ok to halt a phase as soon as rule 3 starts applying.
Once a leaf node is created it will always remain a leaf node, only edge label of the edge between itself and its parent, will keep on increasing because of application of rule 1, and also for all the leaf node the end index (discussed earlier) will remain same, so in any phase rule 1 can also be applied in a constant time by maintain a global end index for all the leaf nodes.
New leaf nodes are created when rule 2 is applied, and in all the extensions in which rule 2 is applied in any phase , in the next phase , rule 1 will be applied in all those extensions.
So a maximum of times rule 2 will be applied as there are leaves, so this means all the phases can be completed in complexity .

Không có nhận xét nào:
Đăng nhận xét