Connectivity in an undirected graph means that every vertex can reach every other vertex via any path. If the graph is not connected the graph can be broken down into Connected Components.
Strong Connectivity applies only to directed graphs. A directed graph is strongly connected if there is a directed path from any vertex to every other vertex. This is same as connectivity in an undirected graph, the only difference being strong connectivity applies to directed graphs and there should be directed paths instead of just paths. Similar to connected components, a directed graph can be broken down into Strongly Connected Components.
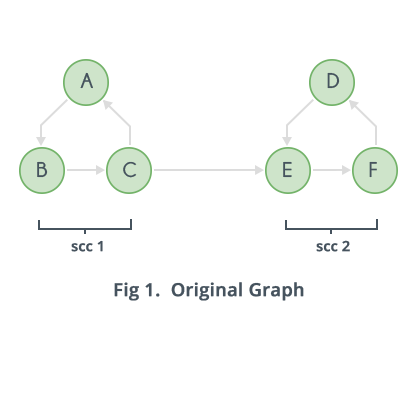
Basic/Brute Force method to find Strongly Connected Components:
Strongly connected components can be found one by one, that is first the strongly connected component including node is found. Then, if node is not included in the strongly connected component of node , similar process which will be outlined below can be used for node , else the process moves on to node and so on.
So, how to find the strongly connected component which includes node ? Let there be a list which contains all nodes, these nodes will be deleted one by one once it is sure that the particular node does not belong to the strongly connected component of node . So, initially all nodes from to are in the list. Let length of list be , current index be and the element at current index . Now for each of the elements at index , assume the element is , it can be checked if there is a directed path from to by a single , and if there is a directed path from to , again by a single . If not, can be safely deleted from the list.
After all these steps, the list has the following property: every element can reach , and can reach every element via a directed path. But the elements of this list may or may not form a strongly connected component, because it is not confirmed that there is a path from other vertices in the list excluding to the all other vertices of the list excluding .
So to do this, a similar process to the above mentioned is done on the next element(at next index ) of the list. This process needs to check whether elements at indices have a directed path to element at index . It should also check if element at index has a directed path to those vertices. If not, such nodes can be deleted from the list. Now one by one, the process keeps on deleting elements that must not be there in the Strongly Connected Component of .
In the end, list will contain a Strongly Connected Component that includes node . Now, to find the other Strongly Connected Components, a similar process must be applied on the next element(that is ), only if it has not already been a part of some previous Strongly Connected Component(here, the Strongly Connected Component of ). Else, the process continues to node and so on.
The time complexity of the above algorithm is .
Kosaraju's Linear time algorithm to find Strongly Connected Components:
This algorithm just does twice, and has a lot better complexity , than the brute force approach. First define a Condensed Component Graph as a graph with nodes and edges, in which every node is a Strongly Connected Component and there is an edge from to , where and are Strongly Connected Components, if there is an edge from any node of to any node of .
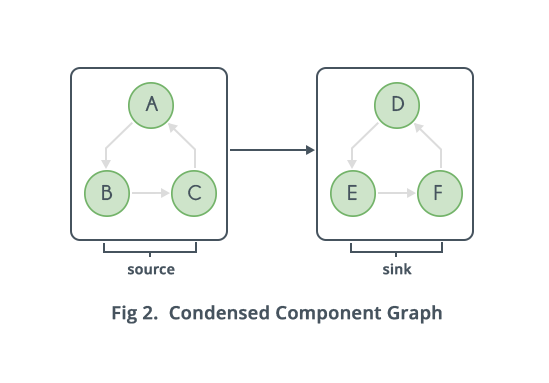
It can be proved that the Condensed Component Graph will be a Directed Acyclic Graph(). To prove it, assume the contradictory that is it is not a , and there is a cycle. Now observe that on the cycle, every strongly connected component can reach every other strongly connected component via a directed path, which in turn means that every node on the cycle can reach every other node in the cycle, because in a strongly connected component every node can be reached from any other node of the component. So if there is a cycle, the cycle can be replaced with a single node because all the Strongly Connected Components on that cycle will form one Strongly Connected Component.
Therefore, the Condensed Component Graph will be a . Now, a has the property that there is at least one node with no incoming edges and at least one node with no outgoing edges. Call the above nodes as Sourceand Sink nodes. Now observe that if a is done from any node in the Sink(which is a collection of nodes as it is a Strongly Connected Component), only nodes in the Strongly Connected Component of Sink are visited. Now, removing the sink also results in a , with maybe another sink. So the above process can be repeated until all Strongly Connected Component's are discovered. So at each step any node of Sink should be known. This should be done efficiently.
Now a property can be proven for any two nodes and of the Condensed Component Graph that share an edge, that is let be an edge. The property is that the finish time of of some node in will be always higher than the finish time of all nodes of .
Proof: There are cases, when first discovers either a node in or a node in .
Case 1: When first discovers a node in : Now at some time during the , nodes of will start getting discovered(because there is an edge from to ), then all nodes of will be discovered and their will be finished in sometime (Why? Because it is a Strongly Connected Component and will visit everything it can, before it backtracks to the node in , from where the first visited node of was called). Therefore for this case, the finish time of some node of will always be higher than finish time of all nodes of .
Case 2: When first discovers a node in : Now, no node of has been discovered yet. of will visit every node of and maybe more of other Strongly Connected Component's if there is an edge from to that Strongly Connected Component. Observe that now any node of will never be discovered because there is no edge from to . Therefore of every node of is already finished and of any node of has not even started yet. So clearly finish time of some node(in this case all) of , will be higher than the finish time of all nodes of .
So, if there is an edge from to in the condensed component graph, the finish time of some node of will be higher than finish time of all nodes of . In other words, topological sorting(a linear arrangement of nodes in which edges go from left to right) of the condensed component graph can be done, and then some node in the leftmost Strongly Connected Component will have higher finishing time than all nodes in the Strongly Connected Component's to the right in the topological sorting.
Now the only problem left is how to find some node in the sink Strongly Connected Component of the condensed component graph. The condensed component graph can be reversed, then all the sources will become sinks and all the sinks will become sources. Note that the Strongly Connected Component's of the reversed graph will be same as the Strongly Connected Components of the original graph.
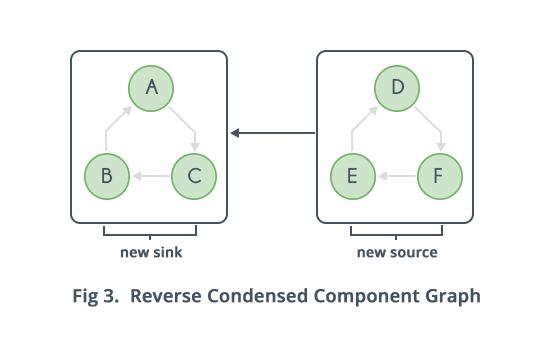
Now a can be done on the new sinks, which will again lead to finding Strongly Connected Components. And now the order in which on the new sinks needs to be done, is known. The order is that of decreasing finishing times in the of the original graph. This is because it was already proved that an edge from to in the original condensed component graph means that finish time of some node of is always higher than finish time of all nodes of . So when the graph is reversed, sink will be that Strongly Connected Component in which there is a node with the highest finishing time. Since edges are reversed, from the node with highest finishing time, will visit only its own Strongly Connected Component.
Now a can be done from the next valid node(valid means which is not visited yet, in previous ) which has the next highest finishing time. In this way all Strongly Connected Component's will be found. The complexity of the above algorithm is , and it only requires .
The algorithm in steps can be described as below:
Do a on the original graph, keeping track of the finish times of each node. This can be done with a stack, when some finishes put the source vertex on the stack. This way node with highest finishing time will be on top of the stack.
stack STACK
void DFS(int source) {
visited[s]=true
for all neighbours X of source that are not visited:
DFS(X)
STACK.push(source)
}
Reverse the original graph, it can be done efficiently if data structure used to store the graph is an adjacency list.
CLEAR ADJACENCY_LIST
for all edges e:
first = one end point of e
second = other end point of e
ADJACENCY_LIST[second].push(first)
Do on the reversed graph, with the source vertex as the vertex on top of the stack. When finishes, all nodes visited will form one Strongly Connected Component. If any more nodes remain unvisited, this means there are more Strongly Connected Component's, so pop vertices from top of the stack until a valid unvisited node is found. This will have the highest finishing time of all currently unvisited nodes. This step is repeated until all nodes are visited.
while STACK is not empty:
source = STACK.top()
STACK.pop()
if source is visited :
continue
else :
DFS(source)
Không có nhận xét nào:
Đăng nhận xét